

Introdução
Uma das dúvidas mais comuns em projetos de IA corporativa é:
“Devemos treinar um LLM com nossos dados ou criar um RAG?”
A pergunta parece simples, mas esconde várias decisões importantes. Na prática, muita gente usa “treinar o modelo” para significar coisas diferentes: treinar um LLM do zero, fazer fine-tuning, colocar documentos em uma base de conhecimento, criar um agente com acesso a arquivos ou conectar uma IA ao ERP.
Essas opções não são equivalentes.
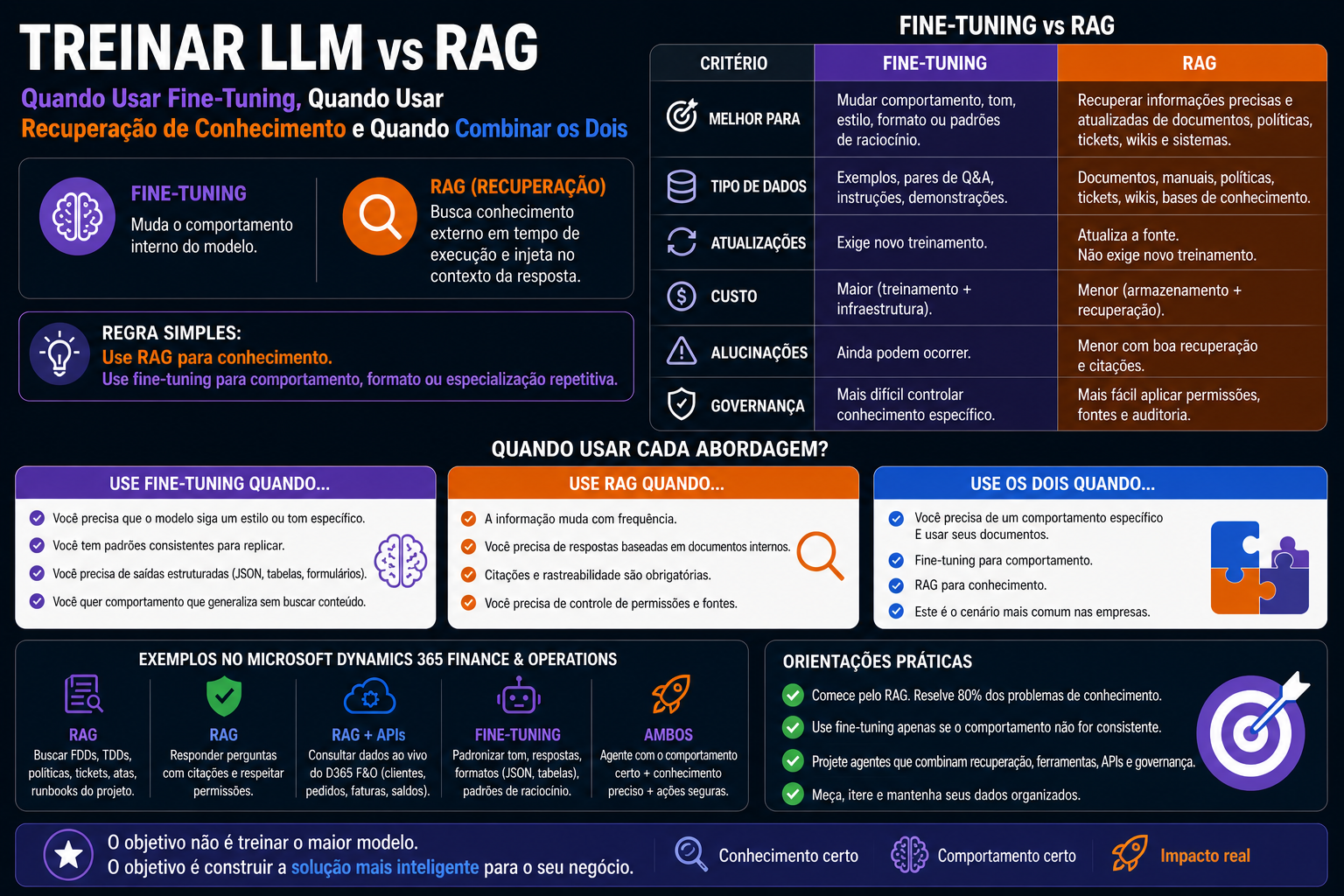
Treinar um LLM muda o comportamento interno do modelo. RAG busca conhecimento externo em tempo de execução e injeta esse contexto na resposta.
Em termos simples:
Use RAG quando o problema é conhecimento. Use fine-tuning quando o problema é comportamento, formato ou especialização repetitiva.
Para empresas que usam Microsoft Dynamics 365 Finance & Operations, essa distinção é crítica. A maioria dos cenários corporativos de ERP não precisa de um modelo “treinado com todos os documentos do projeto”. Precisa de um agente que consiga buscar a documentação correta, citar fontes, respeitar permissões, consultar dados vivos por API quando necessário e agir com governança.
Este artigo compara as duas abordagens, explica quando cada uma faz sentido e mostra como combinar RAG e fine-tuning em arquiteturas de agentes.
Primeiro: O Que Significa “Treinar um LLM”?
Quando alguém fala em treinar um LLM, pode estar falando de pelo menos quatro coisas diferentes.
1. Pré-treinamento do zero
É criar um modelo base novo, treinado com uma quantidade enorme de dados, infraestrutura e custo.
Isso envolve:
- Coletar trilhões ou bilhões de tokens.
- Treinar por semanas ou meses.
- Usar clusters de GPUs.
- Criar pipeline de dados.
- Fazer avaliações de segurança.
- Operar o modelo em produção.
Para a maioria das empresas, essa não é a opção certa. É caro, complexo e raramente necessário.
2. Continued pretraining
É continuar o treinamento de um modelo com um grande corpus específico de domínio.
Pode fazer sentido para laboratórios, fornecedores de modelos ou empresas com domínio extremamente especializado e grande volume de texto. Ainda assim, exige maturidade alta.
3. Fine-tuning supervisionado
É o cenário mais comum quando empresas dizem “treinar o modelo”.
Você pega um modelo pré-treinado e o ajusta com exemplos de entrada e saída:
Entrada: pergunta, contexto ou tarefa
Saída esperada: resposta idealO objetivo é adaptar o modelo a uma tarefa, estilo ou formato.
Exemplos:
- Classificar tickets em categorias.
- Responder em um formato específico.
- Gerar descrições de PR com um padrão fixo.
- Extrair campos estruturados de textos.
- Reescrever mensagens em tom corporativo.
- Transformar logs em diagnósticos padronizados.
4. Preference tuning ou reinforcement fine-tuning
São formas mais avançadas de otimizar comportamento a partir de preferências, avaliadores ou recompensas.
Podem ser úteis para tarefas complexas, mas normalmente entram depois que o time já tem avaliações, dados e critérios bem definidos.
Neste artigo, quando falarmos de treinar LLM, o foco será principalmente em fine-tuning, porque é a alternativa mais realista para empresas.
O Que é RAG?
RAG significa Retrieval-Augmented Generation, ou geração aumentada por recuperação.
O modelo não aprende permanentemente os seus documentos. Em vez disso, o sistema:
- Recebe a pergunta do usuário.
- Busca trechos relevantes em documentos, bases de conhecimento ou índices.
- Envia esses trechos ao modelo junto com a pergunta.
- Gera uma resposta fundamentada nas fontes recuperadas.
Fluxo simples:
Pergunta
↓
Busca em documentos
↓
Trechos relevantes
↓
Prompt com contexto
↓
Resposta com base nas fontesRAG é especialmente útil quando a resposta depende de conhecimento:
- Privado.
- Recente.
- Específico do cliente.
- Atualizado com frequência.
- Que precisa de citação.
- Que precisa respeitar permissões.
Exemplos em D365 F&O:
- FDDs.
- TDDs.
- Runbooks.
- Atas de decisão.
- Documentação de integração.
- Padrões X++.
- Plano de testes.
- Documentação fiscal/localização Brasil.
- Histórico de tickets.
A Diferença Essencial
A diferença mais importante:
| Tema | Fine-tuning | RAG |
|---|---|---|
| O que muda | Pesos/comportamento do modelo | Contexto enviado ao modelo |
| Melhor para | Aprender padrão de resposta ou tarefa | Usar conhecimento externo atualizado |
| Dados | Exemplos de entrada e saída | Documentos, bases e trechos recuperáveis |
| Atualização | Novo treinamento ou nova versão | Atualizar índice ou fonte |
| Citações | Não é natural | Natural, se bem implementado |
| Governança por permissão | Mais difícil | Mais natural com metadados e filtros |
| Conhecimento recente | Ruim sem novo treino | Bom com índice atualizado |
| Custo inicial | Pode ser maior | Geralmente menor para começar |
| Latência | Pode reduzir prompt e latência | Pode adicionar etapa de busca |
| Risco principal | Treinar comportamento errado | Recuperar contexto errado |
Resumo:
Fine-tuning ensina o modelo a responder de um jeito. RAG entrega ao modelo o que ele precisa saber para responder.
Quando Usar RAG
Use RAG quando o principal problema for acesso a conhecimento.
1. O conteúdo muda com frequência
Exemplos:
- Políticas internas.
- Documentos de projeto.
- Decisões de arquitetura.
- Manuais.
- Regras fiscais.
- Runbooks.
- Base de suporte.
Se o conteúdo muda, treinar o modelo com ele é ruim. Você teria que treinar novamente a cada mudança.
Com RAG, você atualiza a fonte ou reindexa.
2. Você precisa de citações
Em ambiente corporativo, resposta sem fonte é fraca.
RAG permite responder:
Segundo o FDD de Procurement, seção 4.3...Fine-tuning não é desenhado para citar a origem de um fato. Ele pode aprender padrões, mas não garante rastreabilidade documental.
3. Você precisa respeitar permissões
Imagine uma empresa com documentos de Finance, RH, Fiscal, Jurídico e M&A.
Nem todo usuário pode acessar tudo.
RAG permite aplicar filtros:
- Por usuário.
- Por área.
- Por projeto.
- Por confidencialidade.
- Por legal entity.
- Por documento.
4. Você quer começar rápido
Um RAG simples pode começar com:
- Documentos.
- Chunks.
- Embeddings.
- Índice.
- Busca.
- Prompt com contexto.
Não exige montar um dataset perfeito de milhares de exemplos.
5. Você está lidando com documentação de ERP
Para D365 F&O, RAG costuma ser a primeira escolha para:
- Perguntas sobre processos.
- Consulta a FDD/TDD.
- Explicação de customizações.
- Decisões de integração.
- Runbooks.
- Testes funcionais.
- Documentação fiscal.
- Onboarding de consultores.
Exemplo:
Pergunta: Por que o projeto decidiu usar integração recorrente em vez de OData para fornecedores?Essa resposta deveria vir de uma decisão documentada, não de fine-tuning.
Quando Usar Fine-Tuning
Use fine-tuning quando o principal problema for comportamento repetitivo, não conhecimento.
1. O modelo precisa responder sempre em um formato específico
Exemplo:
Você quer que o modelo transforme tickets em um JSON rigoroso:
{
"categoria": "Integração",
"modulo": "Finance",
"severidade": "Alta",
"resumo": "...",
"proxima_acao": "..."
}Prompt pode resolver, mas se isso acontece milhares de vezes por dia, fine-tuning pode melhorar consistência e reduzir tokens.
2. Você tem muitos exemplos bons
Fine-tuning precisa de exemplos de qualidade.
Não basta jogar documentos brutos.
Você precisa de pares como:
Entrada: ticket original
Saída: classificação corretaou:
Entrada: trecho técnico
Saída: resposta no padrão desejado3. Você quer reduzir prompt longo
Se você sempre envia o mesmo conjunto de instruções, exemplos e padrões, fine-tuning pode incorporar parte desse comportamento e reduzir o tamanho do prompt.
Isso pode ajudar em:
- Latência.
- Custo por chamada.
- Padronização.
- Aplicações de alto volume.
4. A tarefa é estreita e repetitiva
Fine-tuning funciona melhor quando a tarefa é bem delimitada.
Bons exemplos:
- Classificação de tickets.
- Extração de campos.
- Reescrita em formato padrão.
- Geração de mensagens com tom específico.
- Normalização de descrições.
- Conversão de texto livre em estrutura.
Maus exemplos:
- “Aprenda tudo sobre nosso ERP.”
- “Conheça toda a documentação do cliente.”
- “Responda qualquer pergunta sobre todos os projetos.”
Esses são casos mais adequados para RAG.
5. Você consegue avaliar objetivamente
Fine-tuning sem avaliação é aposta.
Antes de treinar, você precisa saber:
- Qual métrica vai melhorar?
- Qual baseline atual?
- Qual dataset de validação?
- Como detectar overfitting?
- Como comparar modelo base vs fine-tuned?
Tabela de Decisão Rápida
| Cenário | Melhor opção |
|---|---|
| Perguntar sobre documentação interna | RAG |
| Responder com citações | RAG |
| Conteúdo muda toda semana | RAG |
| Respeitar permissão por usuário | RAG |
| Consultar runbooks | RAG |
| Classificar tickets em categorias fixas | Fine-tuning |
| Gerar JSON sempre no mesmo formato | Fine-tuning ou structured outputs |
| Reduzir prompt repetitivo em alto volume | Fine-tuning |
| Ensinar estilo de resposta específico | Fine-tuning |
| Consultar saldo atual no ERP | Tool/API, não RAG nem fine-tuning |
| Explicar política e consultar dado atual | RAG + tool |
| Agente de suporte completo | RAG + tools + possivelmente fine-tuning |
O Erro Mais Comum: Querer Treinar Conhecimento
Muitas empresas pensam:
“Temos milhares de documentos. Vamos treinar um modelo com tudo isso.”
Na maioria dos casos, essa é a decisão errada.
Por quê?
- Documentos mudam.
- Documentos podem estar desatualizados.
- Usuários precisam de fontes.
- Permissões variam.
- Conteúdo pode ser confidencial.
- O modelo pode misturar fatos.
- Atualizar conhecimento treinado exige novo ciclo.
Se o problema é “o modelo precisa saber nossos documentos”, comece por RAG.
Fine-tuning não é uma boa base de conhecimento. Ele é uma técnica de adaptação de comportamento.
O Erro Oposto: Achar que RAG Resolve Comportamento
RAG também não resolve tudo.
Se o modelo:
- Responde fora do formato.
- Não segue o tom esperado.
- Classifica tickets de forma inconsistente.
- Precisa repetir uma tarefa estreita milhares de vezes.
- Usa instruções longas demais em toda chamada.
Então talvez RAG não seja suficiente.
Você pode precisar de:
- Melhor prompt.
- Structured outputs.
- Evals.
- Fine-tuning.
- Regras de pós-processamento.
- Um agente com validação.
RAG entrega conhecimento. Ele não garante, sozinho, disciplina de formato.
D365 F&O: Exemplos Práticos
Cenário 1: Agente de documentação de projeto
Perguntas:
- “Qual foi a decisão sobre integração de fornecedores?”
- “Onde está o FDD de contas a pagar?”
- “Quais customizações existem em SalesTable?”
- “Qual teste valida o bloqueio de crédito?”
Melhor opção: RAG.
Motivo:
- Resposta depende de documentos.
- Precisa de citações.
- Conteúdo pode mudar.
- Permissões importam.
Cenário 2: Classificação automática de tickets
Entrada:
Usuário informa que o batch de integração de notas falhou depois da atualização.Saída desejada:
{
"modulo": "Finance",
"tipo": "Integração",
"severidade": "Média",
"time_responsavel": "D365 F&O",
"acao_inicial": "Verificar batch history e logs de integração"
}Melhor opção: fine-tuning, se houver muitos exemplos bons.
Motivo:
- Tarefa estreita.
- Formato repetitivo.
- Pode ser avaliada.
- Alto volume pode justificar otimização.
Cenário 3: Agente de suporte N2
Pergunta:
O batch de fornecedores falhou. O que devo fazer?Melhor opção: RAG + tools.
Motivo:
- RAG busca runbook e decisões.
- Tool consulta status real do batch.
- Agente compara documentação com estado atual.
- Pode pedir confirmação antes de reprocessar.
Cenário 4: Gerar explicação funcional a partir de código X++
Entrada:
- Trecho X++.
- Nome da classe.
- Módulo.
- Contexto funcional.
Saída:
- Resumo para consultor funcional.
- Processo impactado.
- Testes recomendados.
Melhor opção: depende.
Se há poucos casos: prompt + RAG com padrões internos.
Se o time faz isso em grande volume e tem exemplos bons: fine-tuning pode ajudar a padronizar o formato.
Cenário 5: Consultar saldo atual de fornecedor
Pergunta:
Qual é o saldo atual do fornecedor 1001?Melhor opção: API/tool.
Motivo:
- O dado é transacional e atual.
- Não deve vir de documento.
- Fine-tuning não sabe o saldo.
- RAG pode estar desatualizado.
Arquitetura Recomendada: Não Escolha Cedo Demais
Uma arquitetura madura não começa com “vamos treinar”. Ela começa com avaliação do problema.
Fluxo recomendado:
1. Definir perguntas e tarefas
↓
2. Criar baseline com prompt simples
↓
3. Adicionar RAG se faltar conhecimento
↓
4. Adicionar tools se faltar dado vivo ou ação
↓
5. Medir qualidade com evals
↓
6. Considerar fine-tuning se o problema for comportamento repetitivoEssa ordem evita investimento prematuro.
Como Combinar RAG e Fine-Tuning
RAG e fine-tuning não são inimigos. Em muitos casos, a melhor solução usa os dois.
Exemplo:
RAG:
- Busca documentação do projeto.
- Recupera runbooks.
- Traz decisões de arquitetura.
- Cita fontes.
Fine-tuned model:
- Responde sempre no formato do time.
- Classifica riscos de forma consistente.
- Resume com estilo corporativo.
- Gera saída estruturada.
Tools:
- Consulta D365 F&O.
- Verifica batch history.
- Abre ticket.
- Executa ação com aprovação.Arquitetura:
Usuário
↓
Agente
├─ RAG para conhecimento
├─ Tool/API para dados vivos
├─ Modelo fine-tuned para formato/comportamento
└─ Avaliação, logs e auditoriaEssa combinação é poderosa porque separa responsabilidades.
Comparação Por Critério
Conhecimento atualizado
Vencedor: RAG.
Se a informação muda, atualize a base. Não retreine o modelo a cada alteração.
Comportamento consistente
Vencedor: fine-tuning.
Se você tem muitos exemplos e quer que o modelo siga um padrão de resposta, fine-tuning pode ser melhor.
Citações
Vencedor: RAG.
RAG permite apontar para fonte, documento, seção e trecho.
Segurança por permissão
Vencedor: RAG, quando bem desenhado.
Metadados e filtros permitem respeitar acesso por usuário.
Custo de entrada
Vencedor: RAG, na maioria dos casos.
É mais fácil começar com um índice e documentos do que criar dataset de fine-tuning.
Custo em alto volume
Depende.
Fine-tuning pode reduzir tokens e latência em tarefas repetitivas. RAG adiciona busca e contexto, mas evita treino e mantém conhecimento atualizado.
Dados transacionais
Vencedor: nenhum dos dois.
Use ferramentas, APIs ou conectores.
Manutenção
RAG exige manutenção de fontes, índices, chunks e permissões. Fine-tuning exige manutenção de datasets, versões, avaliações e re-treinos.
Ambos precisam de governança.
Checklist: Antes de Decidir
Responda:
- A resposta depende de documentos ou de comportamento?
- O conteúdo muda com frequência?
- Preciso citar fontes?
- Preciso respeitar permissões por usuário?
- Tenho exemplos bons de entrada e saída?
- A tarefa é estreita e repetitiva?
- A resposta depende de dados atuais de sistemas?
- Preciso executar ações?
- Tenho métricas de qualidade?
- Posso avaliar automaticamente?
- O custo e a latência importam em alto volume?
- Há dados sensíveis no processo?
Decisão:
Se depende de documentos → RAG.
Se depende de dado vivo → Tool/API.
Se depende de formato/comportamento repetitivo → Fine-tuning.
Se depende de tudo isso → Agente com RAG + tools + talvez fine-tuning.Roteiro Prático Para Empresas
Fase 1: RAG básico
Comece com um caso de uso claro.
Exemplo:
Responder perguntas sobre documentação de suporte D365 F&O.Fontes:
- Runbooks.
- Tickets resolvidos.
- Manuais.
- FDD/TDD.
Meta:
- Responder com citação.
- Dizer quando não sabe.
Fase 2: Avaliação
Crie um conjunto de perguntas reais:
- 50 perguntas frequentes.
- Respostas esperadas.
- Fontes corretas.
Meça:
- Recuperou o documento certo?
- Respondeu corretamente?
- Citou fonte?
- Inventou algo?
Fase 3: Melhorar retrieval
Ajuste:
- Chunking.
- Metadados.
- Busca híbrida.
- Semantic ranking.
- Filtros.
- Prompt de grounding.
Fase 4: Adicionar tools
Se o usuário precisa de dados vivos:
- Status de batch.
- Saldo.
- Pedido.
- Ticket.
- Log.
Adicione ferramentas com permissão e auditoria.
Fase 5: Considerar fine-tuning
Só depois avalie:
- O modelo erra formato?
- Há muita repetição?
- Temos exemplos bons?
- O ganho justifica custo?
Se sim, fine-tuning pode entrar.
O Que Eu Recomendaria Para D365 F&O
Para a maioria dos projetos D365 F&O, eu começaria assim:
- RAG com documentação oficial do projeto
- FDD, TDD, runbooks, decisões, testes, integrações.
- Busca híbrida
- Lexical para nomes técnicos.
- Vetorial para intenção.
- Metadados fortes
- Módulo, documento, versão, cliente, legal entity, confidencialidade.
- Citações obrigatórias
- Sem fonte, sem certeza.
- Tools para dados vivos
- D365 F&O, Azure DevOps, ServiceNow, logs, batch history.
- Fine-tuning apenas para tarefas repetitivas
- Classificação de tickets.
- Formatação de respostas.
- Geração padronizada de resumos.
- Extração estruturada.
Essa abordagem reduz risco e entrega valor mais rápido.
Conclusão
Treinar LLM e criar RAG não são caminhos equivalentes.
Fine-tuning muda o comportamento do modelo. RAG entrega conhecimento ao modelo no momento da resposta. Tools conectam o agente a dados vivos e ações.
Em projetos corporativos, principalmente em ERP e D365 F&O, a melhor pergunta não é:
“Devemos treinar ou usar RAG?”
A melhor pergunta é:
“O problema é conhecimento, comportamento, dado vivo ou ação?”
Se for conhecimento, comece com RAG. Se for comportamento repetitivo, considere fine-tuning. Se for dado vivo ou ação, use ferramentas e APIs. Se for um processo completo, combine tudo em um agente governado.
O melhor projeto de IA não é o que usa a técnica mais sofisticada. É o que separa responsabilidades, mede qualidade, respeita segurança e entrega resposta confiável para o negócio.
Fontes Oficiais Consultadas
- OpenAI Docs — Model optimization
- OpenAI Docs — Supervised fine-tuning
- OpenAI Docs — Retrieval
- OpenAI Docs — File search
- Microsoft Learn — Customize a model with fine-tuning in Microsoft Foundry
- Microsoft Learn — Azure OpenAI fine-tuning considerations
- Microsoft Learn — Retrieval augmented generation and indexes in Microsoft Foundry
- Microsoft Learn — Retrieval-augmented generation in Azure AI Search
- Microsoft Learn — Semantic ranking in Azure AI Search